hadoop-3.1.3分布式安装本博客用于存档做hadoop部署的回顾学习笔记,且共享
hadoop-3.1.3分布式安装
1.准备 首先准备三台linux(CentOS7)
Hadoop1: 192.168.49.160
Hadoop2: 192.168.49.170
Hadoop3: 192.168.49.180
1.1修改为静态IP 先去查询当前的网关 修改配置文件
1 2 3 4 5 6 cd /etc/sysconfig/network-scripts dir ifcfg* ifcfg-ens33 vim ifcfg-ens33 或者 vim /etc/sysconfig/network-scripts /ifcfg-ens33
配置文件内容
1 2 3 4 5 6 7 8 9 10 TYPE=Ethernet BOOTPROTO=static #改成static,针对NAT NAME=eno16777736 UUID=4cc9c89b-cf9e-4847-b9ea-ac713baf4cc8 DEVICE=eno16777736 DNS1=114.114.114.114 #和网关相同 ONBOOT=yes #开机启动此网卡 IPADDR=192.168.49.160 #固定IP地址 NETMASK=255.255.255.0 #子网掩码 GATEWAY=192.168.49.2 #网关和NAT自动配置的相同,不同则无法登录
重启网络
1 2 service network restart systemctl restart network.service
查看IP
1.2关闭防火墙 1 2 3 4 5 6 systemctl stop firewalld.service systemctl disable firewalld.service systemctl restart iptables.service systemctl enable iptables.service
检查防火墙状态
1 2 firewall-cmd --state not running
下载安装上传文件插件
1.3修改主机名 三台 都执行以下:
删掉原来的内容修改为Hadoop1 #Hadoop2,Hadoop3查看主机名
1.4修改hosts文件 三台 都执行以下:
删掉原来所有内容,改为以下
1 2 3 4 5 127.0.0.1 localhost ::1 localhost 192.168.49.160 Hadoop1 192.168.49.170 hadoop2 192.168.49.180 Hadoop3
1.5设置免密登录 三台 都执行以下操作:
然后三次直接回车不输入任何内容
1 ssh-copy -id root@Hadoop1
测试
不需要输入密码直接进入说明成功,exit退出
1.6时钟同步 安装
启动定时任务
随后在输入界面键入
1 */1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
2.安装Hadoop,jdk等 (1)在/export目录下创建servers,compress目录 1 2 mkdir -p /export/servers mkdir /export/compress
(2)上传hadoop jdk等的压缩包 1 2 3 # 现在使用rz命令上传hadoop jdk二进制安装包到linux服务器上的compress目录下 rz # 直接回车后会有个文件资源管理器,选择好文件后就开始上传了 # 或使用FinalShell上传至Linux上
(3)解压缩hadoop jdk zookeeper等的压缩包 1 2 3 4 5 6 7 8 9 # 现在运行以下命令将该文件解压到/export /servers目录下 tar -zvxf hadoop-3.1.3.tar.gz -C /export/servers tar -zvxf jdk1.8.0_212.tar.gz -C /export/servers # ---------------------------- # 解压完了,你可以使用$ rm -f hadoop-3.1.1.tar.gz 删除掉该安装资源 # ---------------------------- cd /export/servers # 进入解压目录下 chown -R 777 /export/servers/hadoop-3.1.3 chown -R 777 /export/servers/jdk1.8.0_212 # 修改文件权限
(4)卸载虚拟机自带的jdk 注意:如果你的虚拟机是最小化安装不需要执行这一步。
1 rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
3.配置jdk的环境变量 (1)先获取JDK路径 1 2 pwd /export/servers/jdk1.8.0 _212
(2)打开/etc/profile文件 在profile文件末尾添加jDK路径
1 2 3 export JAVA_HOME=/export /servers/jdk1.8.0_212export PATH=$PATH :$JAVA_HOME /bin
(3)保存后退出 (4)让修改后的文件生效 (5)测试JDK是否安装成功 1 2 java -version java version "1.8.0_212"
4.配置Hadoop的环境变量 (1)获取Hadoop安装路径 1 2 pwd /export/servers/hadoop-3 .1.3
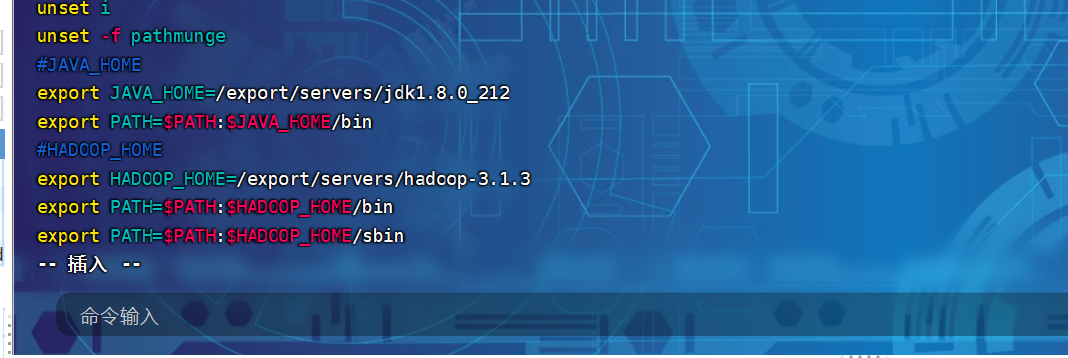
(2)打开/etc/profile文件 在profile文件末尾添加jDK路径:(shitf+g)
1 2 3 4 export HADOOP_HOME=/export /servers/hadoop-3.1.3export PATH=$PATH :$HADOOP_HOME /binexport PATH=$PATH :$HADOOP_HOME /sbin
(3)保存后退出 (4)让修改后的文件生效 (5)测试是否安装成功 1 2 hadoop version Hadoop 3.1 .3
5.修改windows的主机映射文件(hosts文件)(可选) (a)进入C:\Windows\System32\drivers\etc路径
(b)打开hosts文件并添加如下内容,然后保存
192.168.10.160 hadoop1
192.168.10.170 hadoop2
192.168.10.180 hadoop3
6.Hadoop配置-分类 Hadoop目录
1 2 3 4 5 (1 )bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本 (2 )etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件 (3 )lib 目录:存放Hadoop 的本地库(对数据进行压缩解压缩功能) (4 )sbin目录:存放启动或停止Hadoop相关服务的脚本 (5 )share目录:存放Hadoop的依赖jar包、文档、和官方案例
6.1简述 1 2 3 4 hadoop的配置有三种类型: 1. 单机版:即在一个节点(主机)上进行配置一个Hadoop应用使用 2. 伪分布式:即在一台高性能主机上模拟分布式部署去安装多个Hadoop应用 3. 分布式:即在多台主机,各主机之间配置可差异化,每台主机部署一个Hadoop应用
6.2单机版,伪分布式 我懒
6.3完全分布式
Hadoop1
Hadoop2
Hadoop3
HDFS
NameNode,DataNode
DataNode
SecondaryNameNode,DataNode
YARN
NodeManager
ResourceManager,NodeManager
NodeManager
配置集自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
(1)核心配置文件 配置core-site.xml
1 2 cd $HADOOP_HOME/etc/hadoop vim core-site.xml
文件内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://hadoop1:8020</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /export/servers/hadoop-3.1.3/data/tmp</value > </property > <property > <name > hadoop.http.staticuser.user</name > <value > root</value > </property > </configuration >
(2)HDFS配置文件 配置hdfs-site.xml
文件内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration > <property > <name > dfs.namenode.http-address</name > <value > hadoop1:9870</value > </property > <property > <name > dfs.replication</name > <value > 3</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > hadoop3:9868</value > </property > </configuration >
(3)YARN配置文件 配置yarn-site.xml
文件内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.resourcemanager.hostname</name > <value > hadoop3</value > </property > <property > <name > yarn.nodemanager.env-whitelist</name > <value > JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP RED_HOME</value > </property >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log.server.url</name > <value > http://hadoop2:19888/jobhistory/logs</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <property > <name > yarn.scheduler.minimum-allocation-mb</name > <value > 512</value > </property > <property > <name > yarn.scheduler.maximum-allocation-mb</name > <value > 4096</value > </property > <property > <name > yarn.nodemanager.resource.memory-mb</name > <value > 4096</value > </property > <property > <name > yarn.nodemanager.pmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.nodemanager.vmem-check-enabled</name > <value > false</value > </property > </configuration >
(4)MapReduce 配置文件 配置 mapred-site.xml
文件内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > mapreduce.jobhistory.address</name > <value > hadoop2:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > hadoop2:19888</value > </property > </configuration >
(5)配置workers 1 vim /export/servers/hadoop-3.1.3/etc/hadoop/workers
文件内容如下:
(6)配置hadoop-env.sh 在hadoop-env.sh中加入以下内容:
1 2 3 4 5 6 7 export JAVA_HOME=/export /servers/jdk1.8.0_212export HADOOP_HOME=/export /servers/hadoop-3.1.3export HDFS_NAMENODE_USER="root" export HDFS_DATANODE_USER="root" export HDFS_SECONDARYNAMENODE_USER="root" export YARN_RESOURCEMANAGER_USER="root" export YARN_NODEMANAGER_USER="root"
(7)在集群上分发配置好的 Hadoop 配置文件 1 xsync /export/servers/hadoop-3.1.3/etc/hadoop/
7.群起集群 7.1格式化NameNode 如果集群是第一次启动,需要在 hadoop1 节点格式化 NameNode
注意 :格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不 到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。
7.2启动集群 (1)启动HDFS 1 [root@hadoop1 hadoop-3.1.3]$ sbin/start-dfs.sh
(2)启动YARN(在配置了 ResourceManager 的节点上) 1 [root@hadoop2 hadoop-3.1.3]$ sbin/start-yarn.sh
(3)查看集群进程
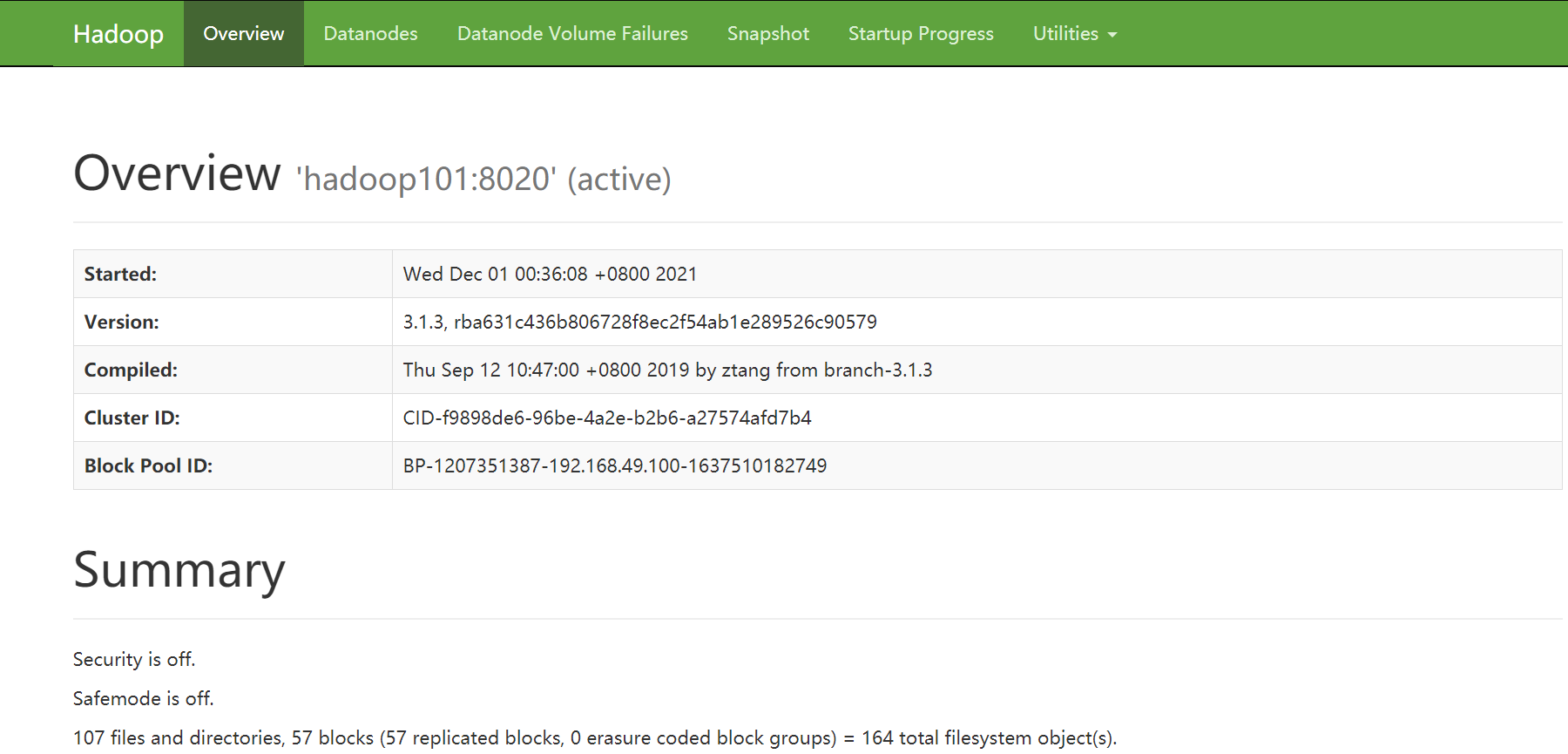
(4)Web 端查看 HDFS 的 NameNode 浏览器中输入:http://hadoop1:9870
(5)Web 端查看 YARN 的 ResourceManager 浏览器中输入:http://hadoop2:8088
7.3关闭集群 1 2 [root@hadoop1 hadoop-3.1.3]$ sbin/stop-dfs.sh [root@hadoop2 hadoop-3.1.3]$ sbin/stop-yarn.sh