SQL语句的语法及使用
主要使用SQL sever 2012
一、SQL简介
SQL 是用于访问和处理数据库的标准的计算机语言。
1,什么是 SQL?
SQL 指结构化查询语言
SQL 使我们有能力访问数据库
SQL 是一种 ANSI 的标准计算机语言
编者注:ANSI,美国国家标准化组
2,SQL能做什么?
SQL 面向数据库执行查询
SQL 可从数据库取回数据
SQL 可在数据库中插入新的纪录
SQL 可更新数据库中的数据
SQL 可从数据库删除记录
SQL 可创建新数据库
SQL 可在数据库中创建新表
SQL 可在数据库中创建存储过程
SQL 可在数据库中创建视图
SQL 可以设置表、存储过程和视图的权限
3,在网站中使用 SQL
要创建发布数据库中数据的网站,需要以下要素:
RDBMS 数据库程序(比如 MS Access, SQL Server, MySQL)
服务器端脚本语言(比如 PHP 或 ASP)
SQL
HTML / CSS
RDBMS
RDBMS 指的是关系型数据库管理系统。
4,RDBMS
RDBMS 是 SQL 的基础,同样也是所有现代数据库系统的基础,比如 MS SQL Server, IBM DB2, Oracle, MySQL 以及 Microsoft Access。
RDBMS 中的数据存储在被称为表(tables)的数据库对象中。
表是相关的数据项的集合,它由列和行组成。
二,SQL语句
注意:SQL对大小写不敏感!!!
1,SQL语句后面的分号
某些数据库系统要求在每条SQL命令的末端使用分号。
分号是在数据库系统中分隔每条SQL语句的标准方法,这样就可以在服务器的相同请求中执行一条以上的语句。
如果使用的是MS Access和SQL Server 2000,则不必在每条SQL语句之后使用分号,不过某些数据库要求必须使用分号。
2,SQL DML和DDL
可以把SQL分为两个部分:数据操作语言(DML)和数据库定义语言(DDL)
SQL(结构化查询语句)适用于执行查询的语法。但是SQL语言也包含用于更新、插入和删除记录的语法。查询和更新构成了SQL的DML部分:select、update、delete、insert into 。 数据库定义语言(DDL)部分使我们有能力创建或删除表格,我们也可以定义索引(键),规定表之间的连接,以及事假表间的约束:
Create database、alert database、create table、alert table、drop table、create index、drop index
三,数据库
1.一个数据库通常包含一个或多个表。每个表由一个名字标识(例如“客户”或者“订单”)。表包含带有数据的记录(行)。
下面的例子是一个名为 “Persons” 的表:
| Id | LastName | FirstName | Address | City |
|---|---|---|---|---|
| 1 | Adams | John | Oxford Street | London |
| 2 | Bush | George | Fifth Avenue | New York |
| 3 | Carter | Thomas | Changan Street | Beijing |
2.用SQL命令创建数据库
创建数据库的SQL命令的语法格式如下所示:
1 | CREATE DATABASE 数据库名称 |
对于上述命令,有以下几点说明:
(1)用[]括起来的语句,表示在创建数据库的过程中可以选用或者不适用,例如,在创建数据库的过程中,如果只用第一条语句”CREATE DATABASE 数据库名称”,DBMS将会按照默认的“逻辑名称” “文件组” “初始大小” “自动增长”和“路径”等属性创建数据库。
(2)“FILEGROWTH”可以是具体的容量,也可以是UNLIMITED,表示文件无增长容量限制。
(3)“数据库校验方式名称”可以是Windows校验方式名称,也可以是SQL校验方式名称。
(4)“FOR ATTACH”表示将已经存在的数据库文件附加到新的数据库中。
(5)用()括起来的语句,除了最后一行命令之外,其余的命令都用逗号作为分隔符。
例3-2-1:
- 用SQL命令创建一个教学数据库Teach,数据文件的逻辑名称为Teach_Data,效据文件存放在E盘根目录下,文件名为TeachData.mdf,数据文件的初始存储空间大小为10MB,最大存储空间为500MB,存储空间自动增长量为10MB;日志文件的逻辑名称为Teach_Log,日志文件物理地存放在E盘根目录下,文件名为TeachData_ldf,初始存储空间大小为5MB,最大存储空间为500MB,存储空间自动增长量为5MB。
1
2
3
4
5
6
7
8
9
10
11
12
13CREATE DATABASE Teach
ON
( NAME=Teach_ Data,
FILENAME='D:\TeachData.mdf',
SIZE=10,
MAXSIZE=500,
FILEGROWTH=10)
LOG ON
( NAME=Teach_Log,
FILENAME='D:\TeachData.ldf',
SIZE=5,
MAXSIZE=500,
FILEGROWTH=5)
3.用SQL命令修改数据库
可以使用可以使用ALTER DATABASE命令修改数据库。
注意,只有数据库管理员(DBA)或者具有CREATE DATABASE权限的人员才有权执行此命令。
下面列出常用的修改数据库的SQL命令的语法格式:
1 | ALTER DATABASE 数据库名称 |
各主要参数说明如下:
- ADD FILE:向数据库中添加数据文件。
- ADD LOG FILE:向数据库中添加日志文件。
- REMOVE FILE:从数据库中删除逻辑文件,并删除物理文件。如果文件不为空,则无法删除。
- MODIFY FILE:指定要修改的文件。
- ADD FILEGROUP:向数据库中添加文件组。
- REMOVE FILEGROUP:从数据库中删除文件组。若文件组非空,无法将其删除,需要先从文件组中删除所有文件。
- MODIFY FILEGROUP:修改文件组名称、设置文件组的只读(READ_ONLY)或者读写(READ_WRITE)属性、指定文件组为默认文件组( DEFAULT )。
- ALTER DATABASE命令可以在数据库中添加或删除文件和文件组、更改数据库属性或其文件和文件组、更改数据库排序规则和设置数据库选项。应注意的是,只有数据库管理员(DBA)或具有CREATE DATABASE权限的数据库所有者才有权执行此命令。
例3-3-1:
- 修改Teach数据库中的Teach_Data 文件增容方式为-次增加20MB。
1
2
3
4ALTER DATABASE Teach
MODIFY FILE
( NAME = Teach_Data,
FILEGROWTH = 20)
例3-3-2:
- 用SQL命令修改数据库Teach, 添加一个次要数据文件,逻辑名称为Teach_Datanew,存放在E盘根目录下,文件名为Teach_Datanew.ndf。数据文件的初始大小为100MB, 最大容量为200MB,文件自动增长容量为10MB。
1
2
3
4
5
6
7ALTER DATABASE Teach
ADD FILE (
NAME=Teach_Datanew,
FILENAME='E:\Teach_ Datanew.ndf',
SIZE=100,
MAXSIZE=200,
FILEGROWTH=10)
例3-3-3:
- 用SQL命令,从Teach数据库中删除例3-3-2中增加的次要数据文件。
1
2DATABASE Teach
Teach_ Datanew4,用SQL命令删除数据库
使用DROP DATABASE命令可以从SQL sever中删除数据库,可以一次删除一个或多个数据库。只有数据库管理员(DBA)和拥有此权限的人员才能使用此命令。DROP DATABASE命令的语法如下:1
DROP DATABASE 数据库名称 [,...]
例3-4-1:
- 删除数据库Teach。
1
DROP DATABASE Teach
5,用系统存储过程查看数据库信息
(1)用系统存储过程显示数据库结构。
可以使用系统存储过程Sp_helpdb来显示数据库结构,其语法如下:使用Sp_helpdb系统存储过程可以显示指定数据库的信息。如果不指定[@dbname=]’name’子句,则会显示在master.dbo.sysdatabases表中存储的所有数据库信息,命令执行成功会返回0,否则返回1。如显示AdventureWorks2012数据库的信息:1
Sp_helpdb [[@dbname=] 'name' ]
1
EXEC Sp_helpdb AdventureWorks2012
(2)用系统存储过程显示文件信息。
可以使用存储过程Sp_helpfile来显示当前数据库中的文件信息,其语法如下:如果不指定文件名称,则会显示当前数据库中所有的文件信息。命令执行成功会返回0,否则返回1。 如显示AdventureWorks2012数据库中的Address表的信息:1
Sp_helpfile [[@filename =] ' name']
1
EXEC Sp_helpfile Address
(3)用系统存储过程显示文件组信息。
可以系统存储过程Sp_helpfilegroup来显示当前数据库中的文件组信息,其语法如下:如果不指定文件组名称,则会显示当前数据库中所有的文件组信息。命令执行成功会返回0,否则返回1。如显示AdventureWorks2012数据库中的所有文件组信息:1
Sp_helpfilegroup [[@filegroupname =] 'name ' ]
1
2use AdventureWorks2008R2
EXEC Sp_helpfilegroup四,数据表
1、Select
User表里面的数据如下:
1,查询user表里面的user_name字段和user_age字段的所有数据:user_id user_name user_age 1 mary 12 3 tom 10 4 alice 14 5 luna 13 2,查询user表中所有的字段数据,用 * 表示列的名称:1
Select user_name,user_age from user
1
Select * from user
2、Distinct
Distinct选取所有的值的时候不会出现重复的数据
用普通的查询,查询所有
1 | Select * from user |
| user_id | user_name | user_age |
|---|---|---|
| 1 | mary | 12 |
| 3 | mary | 12 |
| 4 | alice | 14 |
| 5 | luna | 13 |
1 | Select distinct user_name,user_age from user |
注意:不能有user_id,因为两个Mary的user_id不一样,加上就不算相同数据
5、Where
1,查询user_id等于1的数据
1 | Select * from user where user_id = 1 |
2,查询user_age大于等于12的数据
1 | Select * from user where user_age >=12 |
3,查询user_age不等于12的数据
1 | Select * from user where user_age <> 12 |
4、AND 和 OR
And和or在where子语句中把两个或多个条件结合起来。如果需要两个条件都成立就是用and如果只需要其中一个条件成立就使用or.
1,查询user_name是mary或user_age是12的。
1 | Select * from user where user_name = 'mary' and user_age = 12 |
需要注意的是SQL使用单引号来环绕文本值,如果是数值则不需要引号
2,查询user_name是mary和user_age是13的。
1 | Select * from user where user_name='mary' or user_age =13 |
结合and和or使用圆括号来组成复杂的表达式。
3,查询user_name是mary和user_age是12的,或user_age是13的。
1 | Select * from user where (user_name = 'mary' and user_age = 12) or(user_age =13) |
5,Order by
1,对指定列进行升序排列
1 | Select * from user order by user_name |
2,按照user_id逆序排列
1 | Select * from user order by user_id DESC |
3,按照升序排列user_id逆序排列user_age
1 | SELECT * FROM user order by user_id ASC,user_age DESC |
4,按照升序排列user_id逆序排列user_age
1 | SELECT * FROM user order by user_age DESC,user_id ASC |
注意:前面的条件优先级更高!!
6,Insert
User表:
| user_id | user_name | user_age |
|---|---|---|
| 1 | mary | 10 |
| 3 | mary | 12 |
| 4 | alice | 14 |
| 5 | luna | 13 |
1,插入一行数据 user_id为2 user_name为tom,user_age为12
注意:如果每一项都有插入的话就不需要在前面列出列名!!
1 | Insert into user values(2,'tom',12) |
2,新插入一行数据,只要求user_name为eva
1 | Insert into user(user_name) values('eva') |
| user_id | user_name | user_age |
|---|---|---|
| 1 | mary | 10 |
| 2 | tom | 12 |
| 3 | mary | 12 |
| 4 | alice | 14 |
| 5 | luna | 13 |
| 6 | eva | (NULL) |
注意:因为ID设置为自增,所以user_id不为null
7,Update
1,修改user_id为6的数据user_age为14
1 | Update user set user_age=14 where user_id=6 |
2,修改user_id为1的数据user_name为ann,user_age为11
1 | Update user set user_name='ann',user_age=11 where user_id=1 |
8,Delete
User表中的所有数据信息如下
| user_id | user_name | user_age |
|---|---|---|
| 1 | ann | 11 |
| 2 | tom | 12 |
| 3 | mary | 12 |
| 4 | alice | 14 |
| 5 | luna | 13 |
| 6 | eva | 14 |
1,删除user_age为12的数据
1 | Delete from user where user_age=12 |
2,删除表中的所有数据
1 | Delete from user |
五,数据表(SQL高级教程)
1、Top
Top子句用于返回要返回的记录的数目,但并不是所有的数据库都支持top子句
1,SQL Server
1 | Select top 5 * from user |
2,MySQL
1 | Select * from user limit 5 |
3,Oracle
1 | Select * from user where ROWNUM <= 5 |
2、Like
User表的初始数据如下
| user_id | user_name | user_age |
|---|---|---|
| 1 | mary | 10 |
| 2 | lili | 11 |
| 3 | linda | 12 |
| 4 | harry | 13 |
1,找出以li开头的数据
1 | Select * from user where user_name like 'li%' |
2,找出以ry结尾的数据
1 | Select * from user where user_name like '%ry' |
3,找出含有a的数据
1 | Select * from user where user_name like '%a%' |
4,找出第二个字母是a第四个字母是y的数据
1 | Select * from user where user_name like '_a_y' |
3、通配符
在搜索数据库中的数据的时候SQL通配符可以替代一个或多个字符。SQL通配符必须与like运算符一起使用
1, _ 替代一个字符
找出第二个字母是a第四个字母是y的数据
1 | Select * from user where user_name like '_a_y' |
2, % 替代一个或多个字符
找出以ry结尾的数据
1 | Select * from user where user_name like '%ry' |
3, [] 字符列中的任意一个单字符
找出以a或者l开头的数据
1 | Select * from user where user_name like '[al]%' |
找出不是a或者l开头的数据
1 | Select * from user where user_name like '[!al]%' |
4、In
只要数据满足in里面的一个条件就可以了
1,找到user_age是12或者13的数据
1 | Select * from user where user_age in (12,13) |
2,找到user_name是Harry和Mary的数据
1 | Select * from user where user_name IN ('mary','harry') |
5、Between
选取两个值之间的数据
1,查询年龄在12和14之间的数据
1 | Select * from user where user_age between 12 and 14 |
2,查询字母在Alice和John之间的数据
1 | Select * from user where user_name between 'alice' AND'john' |
6、Aliases
指定别名
假设我们有两个表分别是user和Room 。我们分别指定他们为u和r。
1,不使用别名
1 | Select room.room_name,user.user_name,user.user_age from user ,room Where user.user_age=12 and room.room_id = 1 |
2,使用别名
使用别名的时候直接将别名跟在后面,不使用as也可以
1 | Select r.room_name,u.user_name,u.user_age from user as u,room as r Where u.user_age=12 and r.room_id = 1 |
7、Join
数据库中的表可以通过键将彼此联系起来,主键是一个列,在这个列中的每一行的值都是唯一的,在表中,每个主键的值都是唯一的,这样就可以在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。
以下为表user和表Room的数据
| user_id | user_name | user_age | room_id |
|---|---|---|---|
| 1 | lili | 12 | 1 |
| 2 | tom | 14 | 2 |
| 3 | alice | 11 | 1 |
| room_id | room_name |
|---|---|
| 1 | room of girl |
| 2 | room of boy |
1,引用两个表
找出在Room of boy相关联的用户信息
1 | Select u.user_name,u.user_age,r.room_name from user as u,room as r Where u.room_id = r.room_id and r.room_name='room of boy' |

2,使用关键字join来连接两张表
1 | Select u.user_name,u.user_age,r.room_name |
8、Inner join
Inner join 与 join 用法一致
1 | Select u.user_name,u.user_age,r.room_name |
9、Left join
注意:左连接以左边的表为主体,也就是说会列出左边的表中的所有的数据,无论它是否满足条件。
1,user在左边
1 | Select u.user_name,u.user_age,r.room_name |

2,Room在左边
1 | Select u.user_name,u.user_age,r.room_name |

10、Right join
注意:左连接以右边的表为主体,也就是说会列出左边的表中的所有的数据,无论它是否满足条件。
1,Room在右边
1 | Select u.user_name,u.user_age,r.room_name |
2,user在右边
1 | Select u.user_name,u.user_age,r.room_name |

11、Full join
1,user在左边
1 | Select * from user Full join room |

2,Room在左边
1 | Select * From room full join user |

注意:SQL错误码1054表示没有找到对应的字段名;错误码1064表示用户输入的SQL语句有语法错误
12、Union
Union操作符用于合并两个或者多个SELECT语句的结果集
请注意,UNION内部的select语句必须拥有相同数量的列。列也必须拥有相同的数据类型。同时,每条select语句中的列的顺序必须相同。
下面是Room表和color表的数据

1 | Select room_name from room |

默认的union选取不同的值,如果想要有相同的值出现就使用union all
1 | Select room_name from room |

13、Create DB
创建数据库mysqltest
1 | Create database mysqltest |

14、Create table
1 | Create table sqltest( |


15、Constraints
SQL约束,用于限制加入表的数据的类型
常见约束:not noll、unique、primary key、foreign key、check、default
16、Not null
Not null 约束强制列不接受NULL值。Not null 约束强制字段始终包含值,这意味着,如果不向字段添加值,就无法插入新的字段或者更新记录
用法,在字段后面加上 not null
17、Unique
Unique约束唯一标识数据库中的每一条记录。Primary key约束拥有自动的unique约束。需要注意的是,每个表里面可以拥有多个unique约束,但只能有一个primary key约束
1,MySQL用法,unique(字段名)
2,SQL Server 、 Oracle 、 MS Access在字段后面加
3,命名约束使用constraint
4,已经创建了表之后需要添加约束
1 | ALTER TABLE sqltest ADD UNIQUE(Age) |

5,给已经创建了的表添加约束并命名
1 | ALTER TABLE sqltest ADD constraint unique_name UNIQUE(Age,salary) |
6,撤销约束
MySQL
在没有给约束命名的情况下(上面的age约束)直接使用字段名就可以了
1 | ALTER TABLE sqltest DROP INDEX age |

删除后
在约束有名字的情况下,直接使用名字就可以了
1 | ALTER table sqltest drop index unique_name |

删除后
SQL Server 、 Oracle 、 MS Access
ALTER table 表名 drop constraint 约束名
18、Primary key
Primary key约束唯一标识数据库表中的每一条记录,组件必须包含唯一的值。组件列不能包含NULL值。每个表都应该有一个主键,并且每一个表都只能有一个主键
1,在MySQL中的用法
2,在SQL Server 、 Oracle 和MS Access中的用法
3,为已经创建成功的表创建primary key约束
1 | sqltest (id) |

4,为已经创建成功的表添加主键约束,以及为多个列定义主键约束
1 | Alter table sqltest add constraint pk_name primary key (id,name) |

5,在MySQL中撤销主键
1 | sqltest |

删除后
6,在SQL Server、Oracle、MS Access中撤销主键
1 | Alter table 表名 drop constraint 主键名 |
19、Foreign key
所谓的外键,即一个表的外键指向另一个表的主键
User表
Room表
在user表里面room_id列指向Room表里面的id列。Room表里面的id列是主键,user表里面的room_id列是外键。外键约束用于预防破坏表之间的连接动作,外键约束也能防止非法数据插入外键列,因为他必须是他指向的那个表的值之一。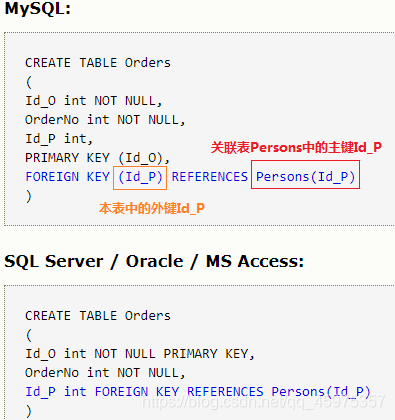
20、Check
Check约束用于限制列中的值的范围。如果对单一的列定义check约束,那么改了只允许特定的值。如果对一个表定义check约束,那么此约束会在特定的列中对值进行限制。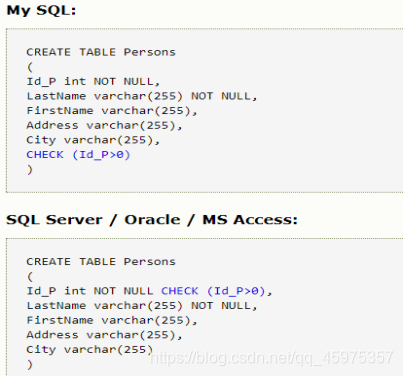
为已经创建成功的表添加check约束
1 | ALTER TABLE USER ADD CHECK (age>10) |
21、Default
Default约束用于向列宗插入默认值。如果没有规定其他值,那么就会将默认值添加到所有的新纪录。
用法:
当表已经存在的时候,添加默认值
1 | ALTER TABLE sqltest ALTER NAME SET DEFAULT 'tom' |


撤销默认值

22、Create index
索引,你可以在表里面创建索引,一边更加快速高效地查询数据。用户无法看见索引,他们只能被用来加速搜索、查询。
注意:更新一个包含索引的表需要比更新一个没有索引的表更多的时间,这是索引本身也需要更新,因此,理想的做法是仅仅在常常被搜索的列上面创建索引。
1,创建一个索引
1 | CREATE INDEX index_name ON color (color_id ) |

2,创建一个独一无二的索引,即两行不能拥有相同的索引值。
1 | CREATE UNIQUE INDEX book_index ON book (book_id) |

3,如果索引不止一个列,你可以在括号中列出这些列的名称,用逗号隔开
1 | CREATE INDEX index_bank ON bank (bank_id,bank_name) |

23、Drop
通过使用DROP语句,可以删掉索引、表和数据库
1,删除索引
1 | Drop index index_name on color |

删除之后


2,删除表
1 | DROP TABLE colorcopy |
 删除之后
删除之后
3,清空表
1 | TRUNCATE TABLE color |
4,删除数据库
1 | DROP DATABASE mysqltest |
24、Alert

1,添加列
1 | Alter table user add salary float |

2,删除列
1 | Alter table user drop column room_id |

25、Increment
定义主键自增
26、View
视图,一种基于SQL语句的结果集可视化表。视图包含行和列,就像一个真实的表。视图中的字段来自一个或多个数据库中的真实的表中的字段,我们可以向视图添加SQL函数、where以及join语句,我们提交数据,然后这些来自某个单一的表。需要注意的是,数据库中的结构和设计不会受到视图的函数、where或join语句的影响
1,创建一个视图,字段来自user表和Room表
1 | CREATE VIEW view_test AS |
2,查询视图
1 | Select * from view_test |

3,撤销视图
1 | DROP VIEW view_test |
27、Date

28、Nulls
默认的,表的列可以存放NULL值。如果表里面的某个列是可选的,那么我们可以在不想改列添加值的情况下插入记录或者更新记录,这意味着该字段以NULL值保存。注意,NULL和0是不等价的,不能进行比较。
1,查询NULL值
1 | select * from user where salary is null |
2,查询非NULL值
1 | select * from user where salary is not null |
六,SQL函数
1、SQL functions
在SQL当中,基本的函数类型和种类有若干种,函数的基本类型是:
合计函数(Aggregate function)和 Scalar函数
Aggregate 函数,函数操作面向一系列的值,并返回一个单一的值。
Scalar 函数,操作面向某个单一的值,并返回基于输入值的一个单一的值。
2、Avg()
求平均年龄
1 | Select avg(user_age) from user |

求大于平均年龄的用户
1 | Select * from user where user_age>(Select avg(user_age) from user) |

3、Count()
返回列的值的数目(不包含NULL)
注意,可以使用as来给count()取一个别名
1 | Select count(user_id) from user |

1 | Select count(salary) from user |

返回值不同的有多少
1 | Select count(distinct user_name) from user |

查询所有列
1 | Select count(*) from user |

4、Max()
返回最大值,NULL不包括在计算中
1 | Select max(price) as max_price from commodity |

5、Min()
返回最小值,NULL不包括在计算中
1 | Select min(salary) poor_man from user |

6、Sum()
返回该列值的总额
1 | Select sum(salary) from user |

7、Group By
用于结合合计函数,根据一个或多个列对结果集进行分组
1 | SELECT cname,SUM(price) FROM commodity GROUP BY cname |

8、Having
在SQL中增加having子句的原因是where不能与合计函数一起使用。用法和where一样
1 | SELECT cname,SUM(price) FROM commodity |

9、Ucase()
把函数字段的值转化为大写
1 | SELECT UCASE(user_name) FROM user |

10、Lcase()
将函数字段转化为小写
1 | Select lcase(user_name) from user |

11、Mid()
从文本字段中提取字符
1 | Select mid(user_name,2,2) from user |

12、Round()
Round函数把数值字段舍入为指定的小数位数
1 | Select round(salary,2) from user |

13、Now()
返回当前时间
1 | SELECT NOW() FROM user |
